
Scaling your Laravel applications
Photo by Siora Photography on Unsplash
This article is part of a series where I build a web application in public. It's called Lumeno and you can follow along with its development on Twitter - @LumenoDev or sign up to be notified when it is launched.
While building Lumeno, I've been taking some time to investigate dos and donts when it comes to dealing with large databases and the applications that use them. This is particularly relevant to me as Lumeno has the potential to become quite big and I don't want to have to worry (too much) about scaling issues.
Being mindful of reality
I think as developers, we tend to assume that anything we build will become massive, and that we will inevitably have to deal with scaling. The simple (maybe sad) truth is that, for 99.9999% of us, this will never happen. Your app will remain either small or medium in size and technical scaling issues won't be a problem that you cannot solve by simply upgrading your server specs.
Okay, but what if you're in that 0.0001%? If so, then you're almost certainly going to be in 1 of 2 scenarios:
Scenario #1
Your app will grow slowly and steadily. If that's the case, you'll be able to spot scaling issues fairly early on using monitoring tools. This will give you time to work on a strategy for handling scale. If your growth happens to be more explosive, you can always throw money at server specs to buy time, or consider migrating to a managed scalable service like PlanetScale. Just be aware that pricing with these services can be surprising (based on row reads) and some things are usually missing e.g. foreign keys / cascade deletes etc.
Scenario #2
The alternative, is that you get massive growth more or less from day 1. In all likelihood, this will only happen if you're a well-known entity that is going to attract major attention e.g. Google launching something. If this is the case, and you're reading this article, your data layer strategy is almost certainly being handled by someone else with tons of experience dealing with scale. You'll be told what to do / use, so you don't need to worry.
Choosing your database
There are a plethora of database systems available these days, but I'm going to focus on the ones that most web applications run on: MySQL and Postgres (SQL Server is also a contender, but since I don't use it, I'm not referencing it here).
Let's take a look at the factors you'll want to consider when choosing a database system:
Performance
In the past, there was a significant gap between MySQL and Postgres. When MySQL used the MyISAM engine, it was slower than Postgres when performing writes, but much faster at reads. However, MyISAM did not include many critical features such as transactions, which is why we now use the modern InnoDB engine instead.
At the time of writing, the latest versions of MySQL and Postgres are now pretty much the same when it comes to performance. When benchmarking, you can probably spot some differences, but in real world use you're unlikely to notice much.
Features
There's no doubt that Postgres is the winner here, as it includes a whole bunch of other functionality, which you may find extremely useful for your application.
I won't go into the additional features that Postgres offers (there are just too many), and there are countless comparison articles on the net, but sufficed to say, unless your app needs a Postgres feature or features, you should be fine using either database system.
Scalability
People love to ask, "will it scale?", and not just about databases. I refuse to be drawn into this flame war. Simple answer, yes they both scale.
Want proof? Instagram uses Postgres. Facebook uses MySQL.
It's also important to note that, regardless of system, most companies that have massive scale are rarely using the stock database code. Instead, they've forked the original project and changed it a lot to meet their needs.
Support
MySQL is definitely more popular, and therefore there are more database admins for it, which makes getting support or hiring easier. That said, Postgres is catching up fast and it isn't really an issue like it used to be.
However, a big counter point for Postgres is that if you want to use shared hosting, then you will have a hard time finding a company that offers it. Mind you, at scale, you won't be using shared hosting...
Summary
In most cases, it doesn't matter which you choose.
The only thing worth mentioning, is that despite both systems being built around the SQL standard, they are not drop-in replacements for each other. If you intend to change, you will need to do some work. However, if you rely on Laravel, or more specifically Eloquent, to do the heavy lifting of DB interaction, then the amount of work shouldn't be too much.
Some practical scaling things to be aware of
In this section, I'm going to address some common scaling ideas and issues. In some cases, I'll be advising of things to be mindful of. In others, I'll be dispelling some approaches that you probably shouldn't be using.
Needless to say, I'll be summarising in this section as I'm not writing an opus. That said, be aware that these topics involve a lot of detail and nuance, so be sure to read from other sources to get a fuller understanding.
A special thanks goes out to Jack Ellis, Tobias Petry, Kevin Hicks, et al, for their insight, which forms a significant part of this section.
1. You probably don't need to use UUIDs, sharding, or other complex setups
Some people rail against using auto-incrementing IDs for primary keys, but in most cases they do the job just fine, certainly when dealing with up to ~1000 writes per second. If you find that you're doing significantly more, then you may need to look into solutions like Twitter's Snowflake, but these introduce complexity that you should try to avoid if at all possible.
Odds are, that if you cannot use auto-increment, you probably have other issues that require you to re-architect your data layer. At this point, you can change to a different approach for creating unique primary keys.
As an alternative to introducing complexity, consider implementing some basic error handling / using the
retryhelper in your application to handle any deadlocks that come about from the auto-incrementing process.
2. Simple write queries are usually not an issue
Following on from point 1, it should be emphasized that running simple queries will not usually lead to auto-incrementing deadlocking issues e.g.
INSERT INTO `users` (`name`) VALUES ('John')
By contrast, slow-running / bulk write queries could run into issues. For example:
INSERT INTO `users` SELECT * FROM `temp`
In these situations, it may be better to use Laravel to perform these write operations in chunks, and then rely on error-handling to retry failed operations.
3. Don't use strings when integers will do
It can be tempting to use string-based constants e.g. for a user's role (admin, staff, customer) and thus store them in the database as strings with the idea that they are more easily-understood.
Unfortunately, database engines are not as fast with strings (even when they are indexed). By contrast, integers are much faster. So, in the case of the above example, use numbers e.g. admin = 1, staff = 2, customer = 3.
If you really want to use strings, then consider using enums, as these allow for string values, but are indexed as integers. Just be mindful that enums are fixed, so if you need to add more options, you'll need to update your table's schema, which could be a costly operation for a large table.
4. Avoid using WHERE LIKE with a wildcard prefix
When you execute a query such as this:
SELECT * FROM `users` WHERE `name` LIKE '%john%'
MySQL has to do a full table scan, even if the name column is indexed. If you absolutely have to go this route, do what you can to limit the possible results by including additional WHERE clauses that can also use indexes e.g.
SELECT * FROM `users` WHERE `organization_id` = 1 AND `name` LIKE '%john%'
Kevin also points out, "in addition to including the where clauses that can use indexes, it helps to make sure that the indexes are set up correctly for the most common queries. Indexes across multiple columns can help make sure the index is correct for the query. For example, if the query is going to query against ColumnA and ColumnB, having a single index for both of those columns together could help.
Be mindful though that if there are too many indexes, or the indexes don't match the query being run, there is no guarantee the database will actually use them, or use the best one for the query."
Finally, it should be noted that if you drop the prefix and just use a suffix, then MySQL can use the index e.g.
SELECT * FROM `users` WHERE `name` LIKE 'john%'
Alternatively, you can opt for Postgres, which includes trigram support. This enables you to perform the first query relatively efficiently as it builds an index by breaking up the values within the name column into groups of 3 e.g. for Alice, you get {ali, lic, ice}. You can learn more about it here:
https://about.gitlab.com/blog/2016/03/18/fast-search-using-postgresql-trigram-indexes/
5. Full-text searching may be an answer, with caveats
Following on from point 4, if wildcard searches must be done and aren't fast enough, then replacing them with a full-text index and search could help. That said, it could have implications when writing to the table, per MySQL docs:
For large data sets, it is much faster to load your data into a table that has no FULLTEXT index and then create the index after that, than to load data into a table that has an existing FULLTEXT index.
6. Transactions are not the enemy
Transactions are extremely useful when you need to perform a bunch of tasks and need to be able to rollback if one of them failed. Unfortunately, they can result in deadlocks (in some situations). That said, there are ways to help with this.
Tobias points out, "each write operation is implicitly a separate transaction if no transaction is manually started. So, if you do 3-4 write operations, you have 3-4 transactions, and each transaction has some write operations as overhead. A single transaction is more efficient because the write operations are bundled."
You can also use retries within your application to run the transaction again in the event of a deadlock.
While deadlocks are annoying, skipping out on transactions in an effort to improve performance / eliminate issues is generally not a good idea. In 99.9% of cases, applications are not designed to handle partial failures that result in corrupt data. You have to ensure they finish. Therefore, you need transactions.
7. When using transactions, consider savepoints
For transactions that take quite some time, consider using savepoints. Think of them just like in a video game. You save, if you die, you go back to the save.
Using savepoints can be a much easier way to solve a problem rather than trying to pre-calculate every error-condition that might occur. Instead, you let the database figure it out.
Here's an article that explains it nicely with some simple graphs:
https://dotnettutorials.net/lesson/savepoint-in-mysql/
8. Decrease the deadlock timeout
If you're still encountering issues, you can use the following command to decrease the deadlock timeout within MySQL:
SET GLOBAL innodb_lock_wait_timeout=100
The supplied value is in seconds. The minimum is 1, default is 50, maximum is 1073741824.
For Postgres, you can use the following command:
deadlock_timeout=1000
The supplied value is in milliseconds. The minimum is 1, default is 1000, maximum is 2147483647.
Why would you want to bring it down? So that deadlocks are resolved earlier and the request can be executed again internally.
9. Ensure your server has lots of storage space
Most of us would think to ensure that the DB has enough CPU and RAM resources available, but we often miss out on the amount of storage available. Even if the database itself is relatively small e.g. 1-2 GB, your server still needs plenty of storage space because of IOPS (Input/output operations per second).
I won't go into too much detail (as I don't know that much about it), but if you're interested, Jack Ellis wrote a big blog post that includes references to IOPS and how important they are. Read it here:
https://usefathom.com/blog/viral
Dealing with lots of data within your app
Let's now take a look at how to handle large data sets in our Laravel application. We'll approach this in two ways, reading and writing.
Reading through large data sets.
As you would expect, the answer is pagination. Laravel offers 3 types: standard, simple and cursor.
Standard pagination
When working at scale, standard is out for a number of reasons. Firstly, it requires 2 queries to run (the first gets the page, the second gets the total number of rows). Secondly because it uses LIMIT and OFFSET, when you have users scrolling to page 20, 30, 40, 50, then the query becomes slower and slower.
Simple pagination
This is much faster as it only uses a single query (doesn't count the number of rows). It does still use LIMIT and OFFSET, however, it only offers back and forward buttons when rendered in your Blade views, so people are less likely to jump to high page numbers as they have to scroll through the preceeding ones first. They can technically still use the query string to go to higher page numbers, but since the UI isn't there, it's less likely.
Cursor pagination
A newer addition, which is the most efficient. By contrast to the others, it uses WHERE clauses to compare the values of the ordered columns contained in the query. This makes it ideally suited to large data sets.
It does have some caveats though... you won't get page numbers (like in standard pagination), your query requires that the ordering is based on at least one unique column or a combination of columns that are unique. Columns with null values are not supported. Finally, query expressions in "order by" clauses are supported only if they are aliased and added to the "select" clause as well.
If you can work within these constraints, then performance at scale will be noticably better.
Writing when traversing large data sets
For this section, I'm simply going to reference a tip I posted on Twitter that covers each of the options available to you. Each of the approaches have pros and cons, which should be considered when making a choice.
It should be noted that these examples are intentionally simple in order to get the point across. In reality, you could accomplish everything these examples are actually doing with a single query, but you get the idea.
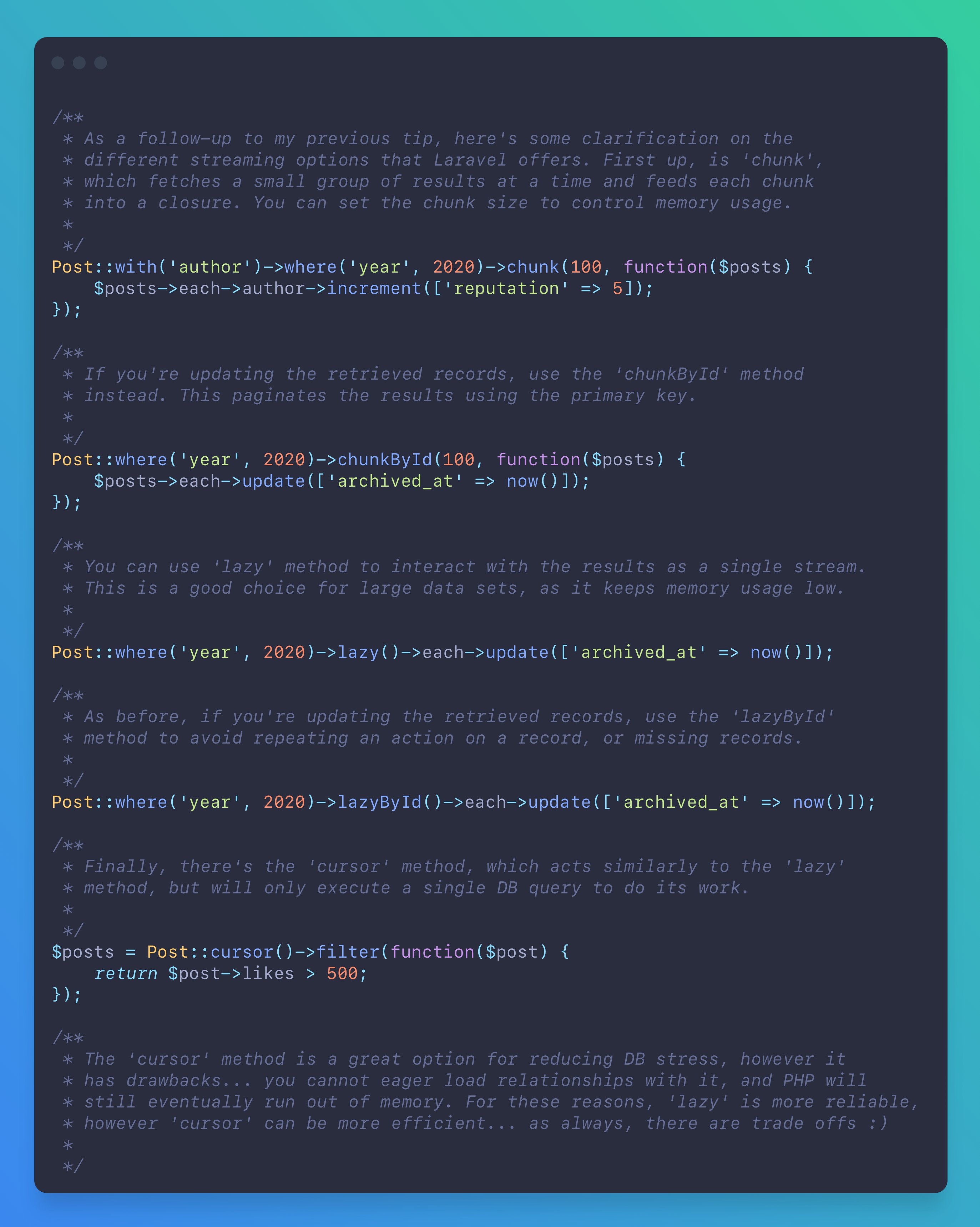
Wrapping up
If you'd like to follow me on my journey of creating Lumeno, and see other coding hurdles I overcome as I get there, then why not follow me on Twitter? I can be found at @mattkingshott.
If you'd like to stay up to date on when Lumeno gets launched, you can sign up at its website.
Thanks for reading, and have a great day ??
Other articles you might like
 June 13th 2026
June 13th 2026
Building a Production MCP Server in Laravel
Spec version notice: This article targets MCP specification version 2025-11-25. The protocol has sh...
 May 30th 2026
May 30th 2026
Evals in Laravel: How to Prove Your AI Output Is Actually Good
You shipped the ticket classifier last quarter. It works. The tests are green and they've stayed gre...
 April 28th 2026
April 28th 2026
Event sourcing with a little help from AI
Event sourcing in Laravel gives you a complete history of your domain, but the hardest part isn't wr...






The Laravel portal for problem solving, knowledge sharing and community building.